What happened so far?
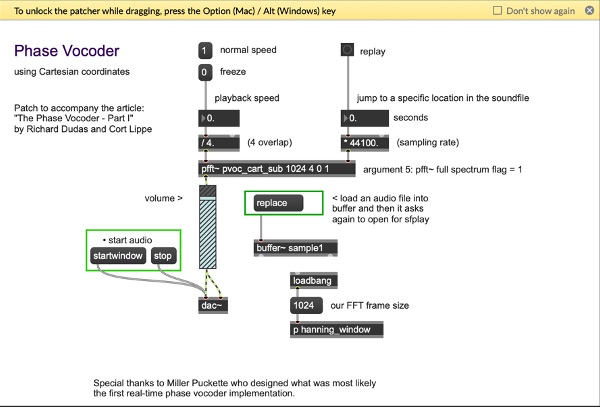
One thing that I found has helped me quite a lot when building my setup was to study and learn from other plug-in constructions that worked with effects similar to the one I am trying to achieve (there’s lots of them available to download for free) for practice. Of course, you could always just look at the connections and figure out what is going on, but for me personally copying them into a new patch object by object and really having to think about which connection was made why helped significantly improve my general understanding of the Max environment, and how I could best organise my complex, growing patches for my own understanding.

To get a cross-platform overview of how the problem can be approached, I also looked at some pure data patches and examined what was done differently there.
Here’s a list of the patchers I learned from:
- Audio Stretcher by kgunessee (in this one I also found out about an external that might become relevant in the next step of my process)
- GrainFreeze by Robert Henke
- GrooveStretch by njazz
- Spectral Freeze by Jean-François Charles
- PolyStretcher by opticon93
- Timestretch Looper by Jesse Engel
- Small_paul1 by Martin Brinkmann (pd)
- dkpaulstretch~ by derekxkwan (pd, based off small_paul1)
- PaulStretch by Jerry Z. Raski (pd)
For Future Reference
I found that the block~ object in puredata seemed like a really useful option for working with FFT sizes and especially FFT sizes that are supposed to be changeable through a parameter, so it might be worth looking into a Max equivalent/alternative for this.
Ongoing
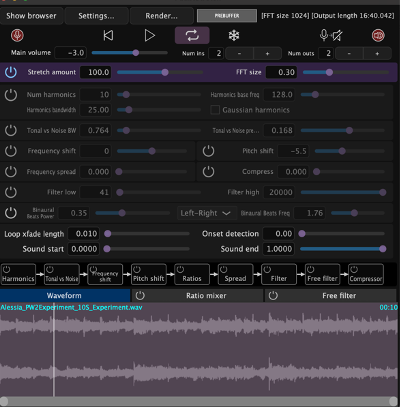
I found that if I am to do a version of the patch for the exhibit, I would like to try it with just one or two parameters in order to prevent information overload for the target audience and make the procedure straightforward and easy to understand. I also used my learning experiences to note down GUI designs that I found easy to navigate, and which constructions worked intuitively for me to inform my own GUI once it is time to create that.
Results and Reflection
While studying these patches dedicated to stretching sound, I found a lot of methods and patching ideas to come closer to an extremely time-stretched result – however, I still found that most of the units did sound close enough to what I wanted to achieve for me to adapt them for my prototype, so this will definitely be a priority for the next stage of the project. Nonetheless, this little excursion helped me get to know my preferred Max workflow a lot, helped me to navigate patches made by others better and gave me new perspectives on problem solving and syntax.
Objectives for Next Time
- look into jitter objects to determine graphical user interface possibilities
- integrate stretch units into the prototype with working signals
- research block~ equivalents and alternatives for Max