To finalise my research, I conducted a short interview with a person to get another perspective on the topic.
The interviewee, after telling me that she is familiar with images generated by artificial intelligence, said that it is mainly those involving nature or landscapes that are very realistic and that she is therefore often unable to distinguish them.
As a designer she has mixed feelings because on the one hand, she thinks AI is a very useful tool that can speed up the work; on the other hand she thinks it is ethically wrong for designers and artists in general.
When I showed her the images I generated using AI, she said that she thought it was normal to get these results because they are based on statistics. At the same time she also acknowledged that they were very stereotypical images.
In conclusion, she stated that she is not sure whether the images generated by artificial intelligence reproduce stereotypes because they are based on statistics and information that people give. However, she then reflected on the fact that society is biased and therefore these images are nothing but a consequence of society itself.
I proceeded with the experimentation to see how AI models represent different cultures.
The images generated by Stable Diffusion always have one factor in common: the people depicted are wearing traditional clothing and/or accessories. Although this may reflect a collective (stereotypical) imagery, in reality people belonging to certain cultures are not always like that, particularly in today’s globalized and cosmopolitan world.
Results of the prompt „Represent a native American“:
Results of the prompt „Represents a person of African descent“:
It is interesting to note that although I used neutral terms, the two prompts generated only male representations in the first case, and only female representations in the second.
I began my experimentation on the topic of professional representation. Using Stable Diffusion, I provided AI with two prompts:
1. “Represent the CEO of a company”
2. “Represent a person who does not work but is dedicated only to household management.”
I chose these prompts because they refer to gender stereotypes in the professional field. For each prompt I generated 3 images.
The first prompt generated 3 images of a white man.
The second prompt generated 1 image of a white woman and 2 images of a white man.
In this case I was surprised because I expected the representations to be only of women, since my prompt was intended to refer to the stereotype of the housewife.
(I highlighted the skin color of the subjects to show how people of color tend not to be represented, as evidenced by numerous studies and data I found at the beginning of my research.)
Having reached this point in my research, after exploring the more theoretical aspects, I intend to proceed to an experimental phase. I will use Artificial Intelligence to generate images related to various thematic areas. The goal will be to verify whether and how the generated images contain biases of a cultural, social, gender nature, etc.
The areas I intend to explore are: job representation, cultural representation, sexual orientation/gender identity, and age representation.
Additionally, I plan to conduct surveys with samples of people to see how these images are perceived, in order to obtain various perspectives on the subject of my research.
In the current context in which artificial intelligence is gaining ground, the Collingridge dilemma clearly manifests itself. The Collingridge dilemma, also known as the dilemma of control, is a conceptual problem in the ethics of technology, formulated by David Collingridge in his book The Social Control of Technology (1980). It highlights the difficulty of predicting and controlling the consequences of a new technology. In the early stages of development and adoption, technologies are relatively easy to modify, but it is difficult to foresee their long-term consequences. As these technologies consolidate and become pervasive, their negative impacts become more evident, but intervening to modify or regulate them becomes much more complex.
Therefore, talking about ai generated images, in the initial phase developers have some degree of control over the training data and algorithms used. However, fully predicting which stereotypes, biases, or harmful beliefs may be present in training datasets sourced from the internet is tough. This lack of knowledge can lead to a poor understanding of the technology’s potential long-term social and cultural impacts.
Once AI-driven image generation technologies are integrated into the design and visual communication environment, it becomes much harder to intervene to correct biases and mitigate dangerous effects. Artificial Intelligence is becoming an integral part of creative and communicative processes, making it difficult to modify without disrupting essential services or significantly influencing professional practices.
Early regulation is likely to be too restrictive for further development and implementation, while regulation at a more mature stage may be limited in its effectiveness and ability to prevent accidents.
Striking the right regulatory balance is crucial, as early intervention may stifle progress while delayed action risks exacerbating existing issues.
Bias: A particular tendency, trend, inclination, feeling, or opinion, especially one that is preconceived or unreasoned. (https://www.dictionary.com/browse/bias)
AI bias refers to AI systems that produce biased results that reflect and perpetuate human biases within a society, including historical and current social inequality. Bias can be found in the initial training data, the algorithm, or the predictions the algorithm produces.
In all AI image generators, the quality of the outputs will depend on the quality of the data sets the millions of labeled images that the AI has been trained on. If there are biases in the data set the AI will acquire and replicate those biases. Studies have shown that images used by media outlets, global health organizations and Internet databases such as Wikipedia often have biased representations of gender and race. AI models are being trained on online pictures that are not only biased but that also sometimes contain illegal or problematic imagery, such as photographs of child abuse or non-consensual nudity. They shape what the AI creates.
Several types of bias can be distinguished:
Selection Bias: it occurs when training data doesn’t represent the reality, often due to incomplete or biased sampling.
Confirmation Bias: AI relies too heavily on existing beliefs or trends, reinforcing biases and overlooking new patterns.
Measurement Bias: Collected data systematically differs from actual variables of interest, leading to inaccuracies.
Stereotyping Bias: AI reinforces harmful stereotypes, like facial recognition being less accurate for people of color.
Out-group Homogeneity Bias: AI struggles to distinguish individuals not in the majority group, leading to misclassification, especially for minority groups.
An analysis of more than 5,000 images created with Stable Diffusion found that it takes racial and gender disparities to extremes — worse than those found in the real world.
As these tools proliferate, the biases they reflect aren’t just further perpetuating stereotypes that threaten to stall progress toward greater equality in representation — they could also result in unfair treatment. Take policing, for example. Using biased text-to-image AI to create sketches of suspected offenders could lead to wrongful convictions.
Therefore, this problem really matters because the increasing use of AI to generate images will further exacerbate stereotypes. Many reports, including the 2022 Recommendation on the Ethics of Artificial Intelligence from the United Nations cultural organization UNESCO, highlight bias as a leading concern.
In the following posts I will analyze more in detail specific cases of AI-generated images that contain biases.
After some initial general introductions to how AI-based image generation works, let’s look specifically at how some of the most popular tools work.
1. Midjourney
Midjourney can convert natural language prompts into high-quality images. In some cases, images from Midjourney have even deceived experts in photography and other domains.
Examples range from Pope Francis dressed in a puffer jacket to Trump arrested, both went viral.
Midjourney begins its image generation process by collecting a vast amount of data. This data includes various elements such as color palettes, lighting conditions, textures, and shapes. The algorithm analyzes this data to understand the underlying patterns and relationships. Once the data is collected and analyzed, Midjourney employs sophisticated pattern recognition techniques to identify recurring patterns and features. This step is crucial in generating images that are visually appealing and aligned with human preferences.
Midjourney continuously learns from its previous iterations and user feedback. It adapts its image generation process based on the insights gained, resulting in improved image quality and realism over time. This iterative learning process enables Midjourney to stay at the forefront of image generation technology.
The magic of Midjourney lies in its ability to combine all the gathered information, patterns, and learned features to create unique and visually striking images. The algorithmic magic ensures that the generated images are not only aesthetically pleasing but also aligned with the desired objectives of the users.
2. DALL-E
Introduced in 2021 by OpenaAI, it revolutionized the world of generative AI. This software can turn a simple text description into photorealistic images that have never existed before, or also realistically edit and retouch photos.
Based on a simple natural language description, it can fill in or replace part of an image with AI-generated imagery that blends seamlessly with the original.
Just like humans can combine the concept of armchair and avocado — and concatenate those concepts into one image, so can DALL-E. In fact, it not only understands individual objects, like koala bears and motorcycles, but learns from relationships between objects.
It can take what it learned from a variety of other labeled images and then apply it to a new image.
DALL-E was created by training a neural network on images and their text descriptions. A text prompt is input into a text encoder that is trained to map the prompt to a representation space. A model called the prior maps the text encoding to a corresponding image encoding that captures the semantic information of the prompt contained in the text encoding. Finally, an image decoder stochastically generates an image which is a visual manifestation of this semantic information.
3. Adobe Firefly
Adobe Firefly generates images from texts. This text generation is currently being used to experiment with features such as Generative Fill in Adobe Photoshop.
Generative Fill doesn’t require a pre-existing image to start working. Users can create images in Photoshop using a text prompt; an image will generate and editing can begin from there. It is a new tool that is definitely changing photo editing.
In conclusion, these tools not only showcase the potential of artificial intelligence to create high-quality, realistic images from textual prompts but also demonstrate their adaptability and continual learning processes. Midjourney’s ability to analyze vast amounts of data and learn from user feedback ensures its ongoing improvement in generating visually appealing images. DALL-E’s innovative approach, utilizing text descriptions to create photorealistic images, opens up new possibilities in image editing and synthesis. Similarly, Adobe Firefly’s integration with Photoshop introduces a novel method of image creation directly from textual prompts, streamlining the creative process for users. As these technologies continue to evolve, they promise to redefine the landscape of image generation and manipulation, offering unprecedented opportunities for creativity and expression in various domains.
Artificial Intelligence image generation techniques use different approaches to create striking and realistic visual works.
GAN
Generative Adversarial Network consist of two competing neural networks: the generator, which acts like a forger that makes fake images and tries to pass them off as real, and the discriminator, which acts like a detective trying to figure out if the generator’s images are real or fake. The generator is asked to create an output of an image that does not exist, which it then tasks the discriminator to figuratively fact-check. The discriminator has been trained on datasets of lots of real images, so it has an idea of what to look out for. When it identifies a fake image, it tells the generator that the generator’s images are real or fake. This process is repeated in a loop until the discriminator can no longer differentiate the generated image from the real thing.
An example is the website This Person Does Not Exist developed in 2018. It produces an image of a random fake face that you can download.
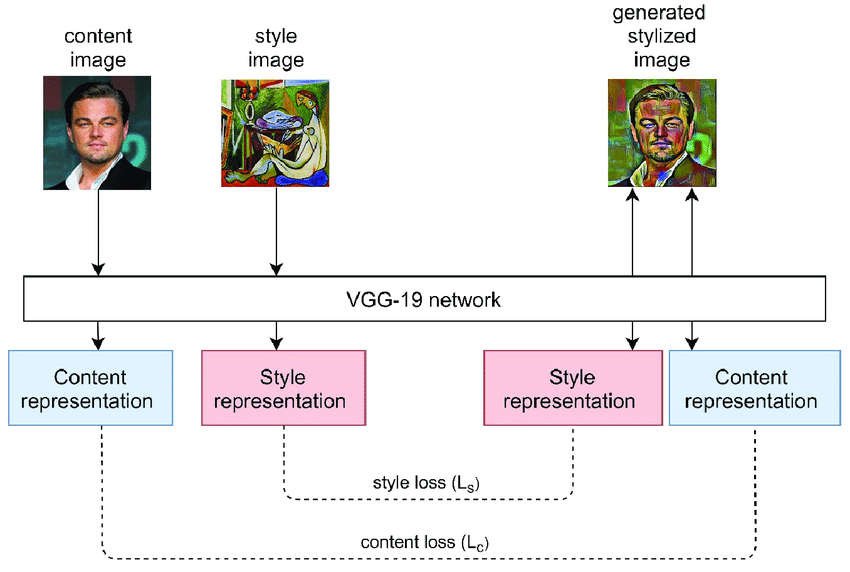
NST
Another method of creating AI-generated images is through Neural Style Transfer. These applications merge the content of one image with the artistic style of another, by utilizing Deep Learning and large datasets.
A Neural Style Transfer works by taking both a Content Image and a Style Image, which are then merged into a generated output. So the resultant image retains the content of the Content Image while adopting the artistic style of the Style Image.
A convolutional neural network, a type of AI that mimics human visual capabilities, is used to extract the features and multiple layers of the content image.
DIFFUSION MODEL
Diffusion Model is used by the most modern image generators applications, such as Stable Diffusion and Midjourney, and it is able to generate high-resolution images. It works by gradually adding Gaussian noise to the original data in the forward diffusion process and then learning to remove the noise in the reverse diffusion process
When we enter a text input into a generative AI app, the software will use Natural Language Processing (NLP) and Machine Learning to understand the prompt. It will then scour a massive library of stock photos and gather images that have relevant text descriptions. Then the AI takes existing images and diffuses the pixels into noise. The AI model is then tasked with rebuilding the original images using the diffused noise blocks, which will result in a new image.
The use of AI-generated images is emerging as an innovative and challenging frontier. AI-generated images refer to visual content that is created using Artificial Intelligence (AI) algorithms and techniques. These images are generated through computational processes rather than being directly captured by a camera or created by human hands. AI-generated images have gained significant attention and traction across various fields, including design and visual communication, due to their ability to produce unique and often highly realistic visual content.
For example, in marketing and advertising, AI-generated images quickly produce campaign visuals. For instance, instead of organizing a photo shoot for a new product, AI can be used to generate high-quality images for promotional materials. For example, in June 2022, the magazine Cosmopolitan released a cover entirely created by AI. The editors collaborated with OpenAI, whose revolutionary DALL-E 2 AI created the image, and digital artist, Karen X. Cheng. The cover image was generated in 20 seconds and finalized within 24 hours, involving human interaction to lay out the text and adjust the proportions within the print cover. This marked the first time an AI-generated image was used as the cover of a major magazine, showcasing the potential of AI in the creative industry.
However, despite the many potentials and opportunities offered by this type of technology, there are also some negative aspects emerging. AI image generator apps are trained on an archive of images sourced from the internet, which may contain stereotypes, biases, and harmful beliefs that the algorithm will use to create artwork. This means that discrimination could become prevalent in generated content, raising ethical concerns.
The focus of my research will be precisely to explore this, as design and visual communication are increasingly adopting AI, and this inevitably leads to cultural/social consequences.